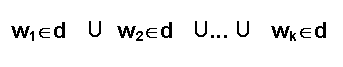| RIPPER Algorithmus |
 |
|
Der Algorithmus besteht aus 2 Stufen:
- Greedy process: erzeugt das anfängliche
Regelset
- Optimierungsprozeß: das Regelset
wird verbessert, der Algorithmus wird kompakter gemacht. Seine Sorgfältigkeit
und Richtigkeit steigern.
|
Stufe I (Generierung des anfänglichen
Regelsets)
Die erste Stufe vom Ripper ist eine
Variante vom Rs Vorfahr- Algorithmus:
IREP (Incremental Reduced
Error Prunning). Es ist ein "set-covering" (Set- deckender)
Algorithmus, der die Regeln eine nach der anderen erzeugt. Der Ripper durchsucht
den Korpus und löscht aus der aktuellen Suche alle Dokumente, die
mit der aktuellen Regel korrelieren (positiv oder negativ). Die heuristische
Methoden dahinter zielen darauf, daß mehrere positive und wenige
negative Beispiele (in unserem Fall Dokumente) durch die Regel entdeckt
werden.
Um eine neue Regel zu produzieren, werden
noch nicht gecheckte Dokumente im Korpus willkürlich in 2 Subsets
geteilt:
"Growing Set" (2/3) und "Prunning
Set" (1/3). Der IREP- Algorithmus läßt die Regel zuerst
wachsen (grows a rule) und danach kürzt er (pruns a rule)
die Konditionen, die die Leistung der Regeln nicht mehr steigern:
|
| GROW¾¾¾¾¾¾®
RULE = Cond1 + Cond2
+
Cond3 +..............+ Condk
¬¾¾¾¾¾¾
PRUN |
Regelwachstum: immer neue Konditionen
werden mehrmalig zur Regel r0 nach Greedy Method addiert,
wobei r0ursprünglich leer war. Greedy Method:
mit jedem Schritt i wird eine Kondition zur Regel ri
addiert so, daß eine neue längere und präzisere Regel ri+1entsteht.
Eine addierte Kondition ist diejenige, die den größten Informationsgewinn
"Information Gain" für ri+1im Vergleich zu
ri
liefert.
"Information Gain" wird folgendermaßen
definiert:
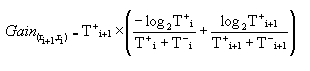
T+i (bzw.
Ti)
ist die Anzahl der positiven (negativen) Beispielen im Growing Set,
die
von der Regel rjgedeckt sind.
Information Gain unterstützt die
Regel ri+1. Als
Folge wird die Dichte der positiven Regel erhöht. Dieses greedy
Wachstum
(Einfügen der neuen Konditionen zur Regel) geht bis zum Punkt, wenn
die Regel keine negativen Beispiele (Dokumente) im Growing Set mehr
entdeckt oder keine Kondition mehr positives Information Gain hat.
Nach dem Growing wird eine Regel
vereinfacht (pruned). Das ist auch ein greedy Prozeß: mit
jedem Schritt i wird ein
Pruning Operator verwendet: entweder
wird eine Konditionsfolge am Ende der Regel ri gelöscht,
oder eine ganze Regel wird eliminiert. Motivation: Senkung der Anzahl von
Fehlern (der falschen positiven Beispiele).
Das Ziel ist die Maximierung von folgender
Funktion:
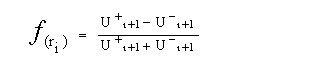
U+i+1(bzw.
Ui+1)
ist die Anzahl der positiven (negativen) Beispiele im Pruning Set, die
von einer neuen Regel erfaßt wird. Pruning hört dann
auf, wenn weitere Eliminierungen zur Erhöhung der Fehlerrate im Pruning
Set führen würden. Nach dem Pruning wird die gekürzte (pruned)
Regel zum Regelset addiert und die von ihr erfaßten Beispiele werden
gelöscht.
|
| Wann soll man aufhören die Regel
zu addieren? |
| Es wird vorausgesetzt, daß Information
Gain nie gleich 0 ist. Das Bedeutet, daß jede Regel einige positive
Beispiele erfassen muß. Das garantiert, daß der Prozeß
irgendwann terminiert wird. Aber mit fehlerhaften (noisy) Korpora
würde es mehrere Regeln geben, die nur wenige Bespiele erfassen. Dies
kann die Berechnungszeit verschlechtern. Für solche Fälle bietet
IREP eine zusätzliche Heuristik an, die versucht, festzustellen, ob
das aktuelle Regelset schon "groß genug" ist. Dieses Stop-Kriterium
ist auf der MDL (minimum description length) Heuristik basierend.
Die Grundidee: das beste Modell unter gegebenen
Datensets ist immer dasjenige, das am kürzesten verschlüsselt
werden kann. Die Datenverschlüsselung geschieht in 2 Schritten: zuerst
wird das Modell verschlüsselt und dann werden auch seine Fehler verschlüsselt.
Nachdem alle Modelle kodiert wurden, wird das beste gewählt: dasjenige
mit der kleinsten Beschreibungslänge (smallest descripton length)
die kleinste Anzahl der Bits, die man für das Encoding braucht.
IREP: Immer wenn eine Regel zum Regelset
addiert wird, wird auch die total description length vom Regelset
berechnet. IREP hört auf, die Regeln zu addieren, wenn diese
Beschreibungslänge 64 Bit größer als die kleinste
Beschreibungslänge ist, die zu dem Moment bekannt ist, oder falls
es keine positiven Beispiele mehr gibt. Das Regelset wird danach so komprimiert,
daß alle Regel durchgegangen werden, angefangen mit der letzten addierten
Regel. Jede Regel, die die Beschreibungslänge erhöht, wird gelöscht.
|
Stufe II (Optimierung des
Regelsets)
Optimierung ist als Prozeß der Reduzierung
des RS und Erhöhung seiner Präzision gedacht.
Die Regeln werden wieder nacheinander
durchgegangen, in der Reihenfolge, wie sie zum Regelset addiert wurden.
Für jede Regel r werden 2
alternative Regeln konstruiert (r,r^).
Regel r - Replacement (Substitution)
für Regel r - wird so wachsen (grown) und gekürzt (pruned),
daß die Fehlerquote im ganzen Regelset minimiert wird, falls man
statt rr nehmen würde.
Regel r^ Revision (Überarbeitung)
für Regel r wird mit greedy Addition von Konditionen
zu r erzeugt.
Danach wird eine Entscheidung getroffen,
welche der drei (Original: r, Replacement: r, Revision:
r^) im endgültigen Regelset bleibt. Es wird wieder mit der
MDL-Heuristik
gemacht: die Variante, die nach der Kompression die kleinste Beschreibungslänge
hat, wird genommen.
Nach der Optimierung kann die Regel weniger
positive Bespiele entdecken als vorher, deswegen wird die IREP (Generierungsstufe)
wieder aufgerufen, um die nicht erfaßten positiven Beispiele zu finden
und alle neue Regeln, die dabei generiert würden, zum Regelset addiert
werden.
Die Optimierungsstufe kann man mehrmals
aufrufen, als Default wird dieses zwei mal gemacht.
|
RIPPER und Textkategorisierung
Für den Einsatz bei Textkategorisierungsproblemen
sollte der Ripper noch angepaßt werden:
-
Loss ratio (Verlustratio): bedeutet
Korrelation zwischen Gewicht von falschen negativen Beispielen und Gewicht
von falschen positiven Beispielen. Die richtige Manipulation von
Gewichten in Pruning- und Optimierungsstufen verbessert Ergebnisse auf
unsichtbaren Daten.
-
Ursprünglich sollte der
Ripper nur ein Regelset von Boolean Features konstruieren können.
Das bedeutet, daß man für jedes Wort wi, das
im Korpus vorkommt (Matrix m × n: m Dokumenten
mit insgesamt n Wörtern), ein Feature bi
erzeugt: den Wörtern werden boolische Werte zugewiesen: true - wenn
das Wort in d vorkommt, und entsprechend false- wenn nicht. Für
die Textkategorisierung ist das ungünstig, da die Dokumente verschiedene
Wörter enthalten und es relativ wenig Wörter gibt, die in beliebigen
Dokumenten vom Korpus vorkommen würden.
Als Lösung werden die Dokumente
als set-valued Attributes repräsentiert diA,
wo die Attributelemente die Wörter sind, die im Dokument vorkommen.
A set-valued Attribut hat ein Set von Strings als Wert. z.B.: colour =
{white, black} |