

Nächste Seite: CISI: Sammlung von Abstracts
Aufwärts: Vergleich mit anderen Retrieval-Methoden
Vorherige Seite: Vergleich mit anderen Retrieval-Methoden
MED ist eine eigens für die Testung von automatischen Retrieval-Systemen
angelegte Sammlung von 1033 medizinischen Abstracts und 30 Queries. Für jedes
Query gibt es händisch zusammengestellte Kollektionen relevanter Dokumente (im
Durchschnitt sind es 23,2 relevante Dokumente pro Query). Wenn 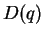 die
Bezeichnung für die Menge relevanter Dokumente zum Query
die
Bezeichnung für die Menge relevanter Dokumente zum Query 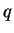 ist und
ist und 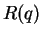 die von einem automatischen Retrieval-System hervorgebrachte Antwort auf ,
dann heißt
die von einem automatischen Retrieval-System hervorgebrachte Antwort auf ,
dann heißt
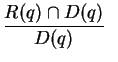
Recall-Wert

und
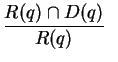
Precision-Wert
des Retrieval-Systems (für das Query ). D.h. der Recall gibt Auskunft
darüber, wie viele von den tatsächlich relevanten Dokumenten vom
Retrieval-System entdeckt werden; die Precision sagt aus, wie viele der (z.T.
fälschlich) entdeckten Dokumente wirklich relevant sind. Beide Werte sollten
so hoch wie möglich liegen.
Drei automatische Retrieval-Systeme wurden auf dem MED-Testset getestet und
hinsichtlich Precision und Recall miteinander verglichen: Das SMART-System
(klassisches Vektorraum-Modell), ein verfeinertes Vektorraum-System nach
VOORHEES (s. [5]) und die LSI-Methode mit 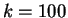 . Die
Systeme unterscheiden sich nicht nur in der Behandlung der Dokumentvektoren,
sondern bereits in der Auswahl der Terme, die in der Term-Dokument-Matrix
Verwendung finden, s. Tab. 1.
. Die
Systeme unterscheiden sich nicht nur in der Behandlung der Dokumentvektoren,
sondern bereits in der Auswahl der Terme, die in der Term-Dokument-Matrix
Verwendung finden, s. Tab. 1.
Tabelle 1:
Termgewinnung bei den MED-Versuchen
| System |
Termgewinnung |
Verwendete Terme |
|---|
| SMART |
Stopwortliste, stemming |
6927 |
| Voorhees |
Stopwortliste, stemming, Termgewichtung |
6927 |
| LSI |
Stopwortliste, kein stemming |
5823 |
|
Für LSI wurden also weniger Terme verwendet als für die anderen
Methoden2. Die Anwendung der drei Methoden führte dann zu
den in Fig. ![[*]](./image.gif) dargestellten Ergebnissen
(dargestellt der Zusammenhang von Recall und Precision).
dargestellten Ergebnissen
(dargestellt der Zusammenhang von Recall und Precision).
Nächste Seite: CISI: Sammlung von Abstracts
Aufwärts: Vergleich mit anderen Retrieval-Methoden
Vorherige Seite: Vergleich mit anderen Retrieval-Methoden
![[*]](./smed.gif) dargestellten Ergebnissen
(dargestellt der Zusammenhang von Recall und Precision).
dargestellten Ergebnissen
(dargestellt der Zusammenhang von Recall und Precision).